Why understanding REST is hard and what we should do about it - systematization, models and terminology for REST
EDIT 29 August 2011: I’ve published a paper on the FSM-based formalism for describing RESTful systems at the ICWE 2011 conference. The formalism presented in the paper is a more detailed and advanced version of the one presented in the second part of this blog post. Links for downloading the paper and presentation slides are in the talks and papers section.
EDIT 25 January 2012: I’ve published another paper on the FSM-based formalism for RESTful systems, this time in the Journal of Web Engineering. This paper is again a revised and extended version of the previous paper. Furthermore, the paper explores the practical challenges and benefits of using the presented formalism. Again, for more details see the talks and papers section.
This is going to be another long post, so I’m using the introduction as an overview again.
Introduction
This post is about understanding REST, the software architectural style behind the World Wide Web. My Ph.D. research, which I'll write about some other time, pushed me on the road of REST and over the last year I've been reading lots of research papers, lots of blogs, lots of mailing lists, lots of tweets, lots of videos, wikis, books and IRC transcripts on REST and I've also recently started the This Week in REST wiki and blog. In other words, I've read almost everything I could find on REST. So, in the first part of this post I'll write about several thoughts which stuck with me while researching REST:
- REST is and will continue to be important - it's the foundation of the WWW and will be the foundation of its future stages and dimensions, like the Semantic Web and the Web of Things.
- Understanding REST is hard - the material on REST is fragmented and there is no clearly defined and systematized terminology or formal models used in discussions.
- We can and should fix the problem - there are enough motivated and smart people who can, through an open and collaborative process, create a better way of fully understanding REST.
In the second part of the post I'll add to the pile of scattered fragments on understanding RESTful systems and describe an abstract model of a simplified REST user-agent using finite state machines. It's a very basic model but serves the purpose of showing that it is both possible and useful to develop such formal models.
I hope this post will motivate people involved and interested in REST to contribute to a process for improving the understanding of REST. I was planing to write my thoughts as a paper for the First International Workshop on RESTful Design (WS-REST 2010) but didn't have enough time. Nevertheless, I hope that people who are going to the workshop will talk about this issue. I'll start a thread on the REST mailing list for following up on these ideas, so please comment there if you want to join the discussion (EDIT: thread is here).
Representational State Transfer and why it's important
Although this post is about understanding the REpresentational State Transfer (REST) software architectural style, I'm not going to write another REST introduction. If you don't know anything about REST, start from the wikipedia article and go from there.

What's more important for this post is that REST is and will continue to be an essential part of the WWW. First, through the Web's core technologies, REST is responsible for most of the good properties of the current Web as a large-scale network-based system. Second, REST principles guide the development of both the next "major" generations of the Web, like the Semantic Web, the Web of Things and the Real-time Web, and the "minor" incremental changes of continuous evolution. Whereas the Semantic Web is about exposing and interlinking data on the WWW, the Web of Things is about connecting and exposing every physical thing to it and the Real-time Web is about real-time access to that data and things. Therefore, understanding the Web today, it's future evolution and the whole technology jungle on top is based on the understanding of REST. Third, REST is important as a research subject on its own (although some people think it isn't EDIT: Subbu elaborated on this misunderstanding below in the comment section) and will be analyzed and built upon to define new architectural styles.
Understanding REST
In my experience, understanding REST is far from easy. Of course, not everyone needs to understand REST and different people may want or need to understand REST at different levels and depths. However, despite it being a highly technical and academic concept not everyone should easily and fully grasp, I think it's hard even for people aimed at - computer scientists, software engineers and web architects. After reading everything I could find on REST and the WWW, here are the problems I believe are responsible for this:
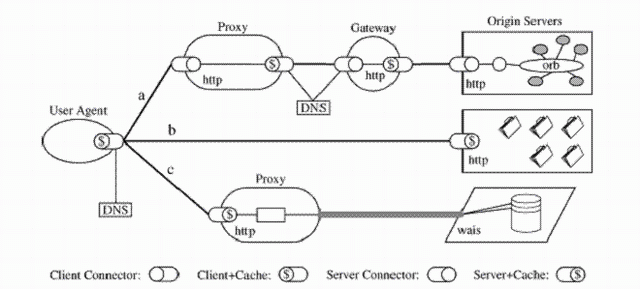 First, the REST master reference, Roy Fielding's doctoral dissertation (and subsequent academic papers), is not completely suitable for fully understanding REST. For a doctoral dissertation, it's severely lacks images explaining important concepts in the two key sections on REST. However, I bet everyone knows the single image in those sections almost by heart from how much it's being repeated everywhere (for those who don't, that's the image on the right). The same could be said for the lack of (formal) models to describe specific properties, elements or views of REST, like HATEOAS. It's as if the very clean and systematic approach of explaining software architecture and network-based architectural styles present in the first few chapters of his Ph.D. somehow vanished in those two sections. I am aware that there are no formal models for defining architectural styles as a whole (at least, there weren't any then), but using models like state machines, Petri nets or process calculi to describe and explain parts of it would have definitely been of great benefit. It's that absolute clarity of formal models that helps when you need to have a complete grasp of a concept. Furthermore, since models are abstract methods for explaining specific problems, people only need to research the underlying model after which the specific use of the model is unambiguously clear. And just to be clear, I think Roy's dissertation is overall well written and has had a big impact on both the academia and industry, and I very well know that making everyone on the planet happy with a research paper is idiotic (looking for a good Ph.D. comics reference for this), but I still wish those two sections were a bit more thorough and polished.
First, the REST master reference, Roy Fielding's doctoral dissertation (and subsequent academic papers), is not completely suitable for fully understanding REST. For a doctoral dissertation, it's severely lacks images explaining important concepts in the two key sections on REST. However, I bet everyone knows the single image in those sections almost by heart from how much it's being repeated everywhere (for those who don't, that's the image on the right). The same could be said for the lack of (formal) models to describe specific properties, elements or views of REST, like HATEOAS. It's as if the very clean and systematic approach of explaining software architecture and network-based architectural styles present in the first few chapters of his Ph.D. somehow vanished in those two sections. I am aware that there are no formal models for defining architectural styles as a whole (at least, there weren't any then), but using models like state machines, Petri nets or process calculi to describe and explain parts of it would have definitely been of great benefit. It's that absolute clarity of formal models that helps when you need to have a complete grasp of a concept. Furthermore, since models are abstract methods for explaining specific problems, people only need to research the underlying model after which the specific use of the model is unambiguously clear. And just to be clear, I think Roy's dissertation is overall well written and has had a big impact on both the academia and industry, and I very well know that making everyone on the planet happy with a research paper is idiotic (looking for a good Ph.D. comics reference for this), but I still wish those two sections were a bit more thorough and polished.
Second, since Roy's dissertation doesn't have clear answers for all questions, people start discussions over understanding specific parts of REST all over the Web. Relevant discussions are scattered over many mailing lists, blogs, Twitter accounts, wikis, academic papers, videos and even IRC transcripts (see the introduction for links to some of these). More often than not these discussion are not focused on REST per se, but on anything related to the Web, various specifics concerning current and future standards and so on. And even more often, the discussions unnecessarily repeat previous discussions probably because the authors are unaware that the same discussion exists elsewhere or it's that those are too difficult to search for. For example, the HATEOAS constraint is getting a lot of attention everywhere. So there's lots of unorganized, scattered, duplicated and mutually disconnected fragments on REST and it's unclear where and how to find the ones that answer your questions. No, Googling won't help as often as you'd like, no, a series of unrelated articles piled up together won't either (though Mike Amundsen's tweets often will), and yes, a-big-unorganized-mess is kind of the point of the Web in general, however it's not the optimal methodology for systematizing knowledge in a way required for understanding complex concepts like REST.

Third, these fragments on REST often use mutually different terminology, same terminology with different meaning or terminology which is not explicitly defined. My favorite example is the word "state" which is overloaded with unexplained and overlapping meaning. "Resource state", "session state", "control state", "client state", "server state", "application state", "transaction state", "steady state" and "transient state" are some of the terms used and it is not completely clear what some of those mean, how they are related and which REST elements use, change and transfer them and when. For example, what is client state? Is it something related to the client connector type? Is it something stored on the client component? If so, then why is it not called user agent state? Is client state a union of session and application state? Or is application state a synonym for session state? Which states does a steady state relate to - client, session or application? Which entities may change session state and when? Yes, some of these concepts are completely clear, but some are not and different people use them with different meaning. Still, the most entertaining situations are the ones in which people write only "state" and then you have to figure out which state they are referring to. Yeah, good luck. And there are other both simple and complex examples, from stating that REST methods are to be executed over representations instead of resources and discussing if ATOM is RESTful or not to explaining just what is an application in terms of REST. Lastly, similar to Roy's dissertation, these discussion rarely use diagrams or formal models to explain anything.
These problems confuse people trying to learn REST on a basic level and make it hard to discuss REST on deeper levels.
What we should do about it
Now, I'm not implying that these problems will cause the apocalypse if we don't solve them, but I'd sure like it if they go away (and lots of other people would also). So here are my suggestions:
First, a mess is still better than nothing. Everyone should at least continue with thinking, writing and talking about REST and create more fragments. Chances are that those fragments will help a fair amount of people interested in REST. I definitely learned a lot from reading excellent blogs, tweets, papers and mailing list posts (Ryan's explanation of REST to his wife is especially entertaining, besides educational).
Second, I think this problem can and should be solved collaboratively and openly, not by single person (not even Roy Fielding) or as just another academic paper. If there's going to be agreement over terminology, it's meaning, models, and other ways of making understanding REST easier, this agreement must be backed by people who have relevant REST experience and must be open to comments from everyone else. Furthermore, untangling the mess will require a lot of work. So, in my opinion, the REST community (whatever that is) should:
- Agree that there is a problem worth fixing - do we think that we can create a better, clearer and more systematized way of understanding and discussing about REST?
- Express interest in fixing it - is this something people want to contribute their time to?
- Agree on how to fix it - what should be our output (a RESTopedia, a document, video tutorials) and how would we all contribute to and moderate the process?
- Do it - spend time discussing and developing the output.
- Eat our dogfood - use whatever we produce. If we don't use the terminology and models we agree upon, the the mess has only gotten bigger.

There are more than enough smart and motivated people with different backgrounds and experience with REST and RESTful HTTP to make this happen and it would have a big impact if done (even more if done right). I myself am not sure what the best output would be and how to achieve it, but would like it to be a hypermedia document available freely on the WWW, contain a systematized intersection of terminology, images, models and rationale that everyone agrees upon and focus on REST, using HTTP/URI/HTML only for examples (not the other way around).
Formal models for REST - a FSM model of a simplified RESTful user-agent
First off, developing useful formal models for understanding architectural styles isn't easy since architectural styles are named sets of constraints commonly defined using natural language, rarely using formalisms. Also, models of REST concepts should include as many other REST concepts as possible - e.g. a model of HATEOAS should somehow clear up how application state, representations, methods, resources, steady states, transient states and other concepts all play their role in HATEOAS. It's not easy to model this in a clear and simple way. Nevertheless, these kinds of models are especially important since they connect rather than disperse concepts.
Mike Amundsen's and Jan Algermissen's poking at REST steady states was very thought-provoking for me - excerpts pointing at something often ignored when discussing REST, but could be formally defined. This led me to try to model REST user-agents using some kind of a state machine. I soon found out there are lots of interesting papers on modeling hypermedia applications in general and even more blogs on modeling REST user-agents using some kind of state machine formalism (FSMs, statecharts, Petri nets or something else). Here are some of my thoughts after reading these papers and blogs:
- Most often, models are based on the "each page is a state and each link is a state transition" analogy. This is confusing and wrong for two reasons. First, it's confusing since resource identifiers (e.g. URIs) are used to somehow address states of the application (e.g. an URI addresses a page which is mapped to a state) and state transitions (e.g. an URI is a link to a state which is mapped to a transition). In REST, resource identifiers are neither the single thing determining the state (e.g. two clients can perform the same GET request on a resource and get different representations which determine state) nor the single thing determining the transition between states (e.g. one client can perform a GET on a resource, the other could perform a PUT). Roy's thesis defines what constitutes application state and thus when the state changes: "An application's state is therefore defined by its pending requests, the topology of connected components, the active requests on those connectors, the data flow of representations in response to those requests, and the processing of those representations as they are received by the user agent." Second, models often ignore some REST concepts like steady and transient states and are therefore useful only for understanding REST up to a certain level.
- State machines models are extremely simple to understand and a powerful tool for modeling. For example, state machines can also be used for model checking using temporal logic (e.g. check that from any state there is a link to the home page).
That's why I really like Stu Charlton's recent post on RESTful user-agents which identifies different types of state machines involved in user-agent operation. Stu nailed most of the things I wanted to write about, but nevertheless - below is my first attempt at a simplified finite state machine (FSM) model of RESTful user-agents. I won't go into explaining FSMs in detail, so just check the Wikipedia article if you don't know what FSMs are.
I'll concentrate on recognizer-type finite state machines - specifically, nondeterministic FSMs (NFAs). NFAs are mathematically defined as a quintuple (Σ,S,s0,δ,F), where
- Σ is the input alphabet (a finite, non-empty set of symbols).
- S is a finite, non-empty set of states.
- s0 is an initial state, an element of S.
- δ is the state-transition function: δ : S x Σ → P(S) where P(S) the power set S.
- F is the set of final states, a subset of S.
The operation of an NFA automaton, as state machines are sometimes called, is described as follows. The NFA starts from the initial state and then sequentially reads one input symbol at a time each time applying the state-transition function to transfer itself to the next state. After all input symbols have been processed in this way, the NFA stops and outputs "true" if the last state is in the set of final states, or "false" otherwise. Notice that it is not defined how input symbols are generated, just that there is a sequence of them being fed to the automaton. Also notice that NFAs can nondeterministically transfer to a set of states at some point. This nondeterminism is important but also confusing - how can the automaton be at more than a single state? Well, although the formal definition indicates that the automaton is in a set of states, the practical and useful meaning is that the automaton may be at any single state from that set - we don't know which one in advance, it can be any single one. In other words, a single state from the set will be chosen in some way e.g. using probabilities.
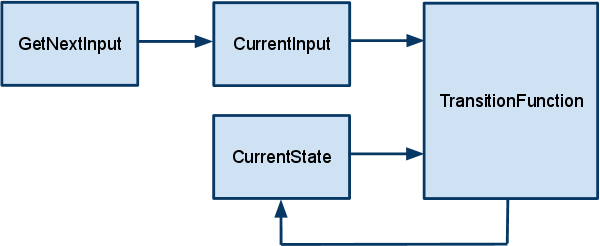
This iterative process of automaton operation can be modeled as a system:
CurrentState = s0
while there are more input symbols to process:
InputSymbol = GetNextInput()
CurrentState =
TransitionFunction(InputSymbol, CurrentState)
|
|
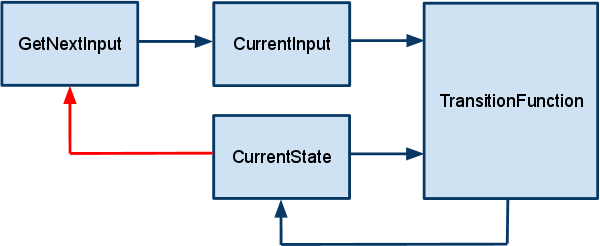
Here, CurrentState is a component that stores the current state of the automaton, InputSymbol is a component that stores the current input symbol (element from the input alphabet), GetNextInput is a component that provides the next input symbol and writes it to the InputSymbol component and TransitionFunction is a component that computes the state transition function and writes the new state to the CurrentState component. Notice that the GetNextInput component doesn't take any input in this description. This is not entirely true, of course - the operation of the component that generates input symbols is out of scope of formal automaton definition, the component may generate input symbols based on whatever it wants. So, I'll expand the system to include the CurrentState as an input to the GetNextInput component (since there is nothing else in the model to include):
CurrentState = s0
while there are more input symbols to process:
InputSymbol = GetNextInput(CurrentState)
CurrentState =
TransitionFunction(InputSymbol, CurrentState)
|
|
Now the interesting part - mapping properties of RESTful user-agents to this NFA model. As I wrote before, this is a simplified first-draft-quality model, not everything that should be included is included and thus the model may change when more details do get included. First I'll try to explain the mapping in a general way, not on a specific RESTful system, and after that I'll give a concrete example:
- The input alphabet (set of input symbols generated by the GetNextInput component and stored in the InputSymbol component) are REST requests. Since a REST requests is defined by a resource identifier, method to be performed on the resource, metadata and a possible representation, the input alphabet is the set of all possible (syntactically) well-formed REST requests. This is why the resource identifier is not the only thing representing a transition - a single transition from a specific state is defined by all elements of a REST request, only one of which is the resource identifier. Therefore, there may be multiple transitions from a specific state and a specific destination resource identifier.
- The state transition function, implemented in the TransitionFunction component, is the cumulative processing of REST requests. This process is performed by user-agents, intermediaries and origin servers, and the result is a REST response containing metadata and a representation of the resource identified in the related REST request. Here's the most important part - since the user-agent doesn't know what the response to a request will be and since the origin server may return different REST responses for the same REST request - this processing must be modeled as nondeterministic. In other words, the result of the transition function is a set of all possible REST responses which may be returned for a given REST request. As I explained earlier when demystifying nondeterminism, the origin server will in fact return a single response but since we don't know which one - this is modeled as a set of possible responses. Also, the metadata (media type) of the response defines if the state is steady or not by specifying which of the resources linked to from the response representation should also be requested. If the state is not steady, more requests should be sent for those resources. If the input symbol is a REST request for a resource for which there is no link in the current state then the transition function returns an empty set. The same happens if the system is not in a steady state and the input symbol is a REST request not in the set of pending requests.
- The current state, stored in the CurrentState component, is a set of REST responses and pending REST requests. The current state is considered a steady state if there are no pending requests, otherwise it's considered a transient state. The initial state of the user-agent is steady and may contain a predefined representation with links to bootstrap the operation of the user-agent.
- The only thing left is to define how the user-agent chooses transitions - the next REST request for the current state. This is the role of the GetNextInput component which implements both application- and hypermedia-level logic. The application-level logic is in charge of generating input symbols in case the current state is steady, or in other words, it chooses then next step for achieving the overall application goal. The application-level logic may be a software program or a program that delegates this responsibility to a human user. The hypermedia-level logic is in charge of generating input symbols in case the current state is transient, or in other words, it chooses which of the pending REST requests will be processed next. To satisfy the HATEOAS constraint, both the application- and hypermedia- level logic generate REST requests with resource identifiers linked to from the current state.
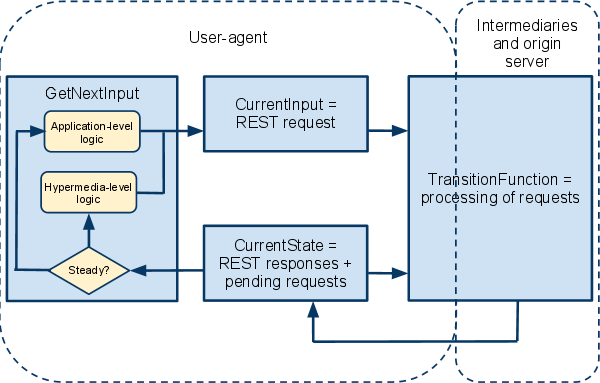
Or mathematically (without all the detailed explanations):
- Σ = { R | R is a valid REST request consisting of a resource identifier, method, metadata and representation }
- S = { { G } | G is a valid REST response consisting of metadata and a representation or a pending REST request }
- s0 = initial representation containing links to bootstrap the operation of the user agent
- δ : S x Σ → P(S) where P(S) the power set of S.
- F = { Z | Z ∈ S and Z is a steady state }
The operation of the automaton can be described as follows. The automaton starts from the initial steady state containing links for bootstrapping the application. Each time the automaton is in a steady state, the application level logic generates the next input symbol (request) based on the links in the current state representations and the overall application goal. The request and the current state are used by the processing infrastructure (user-agent, intermediaries, origin server) to generate a response. Notice here that the current state (representation already on the client) need not be sent to the server, it may be used on the user-agent for processing (e.g. to determine if the request is for a resource linked to from the current state or not) while only the input symbol (the request) is sent over the network. The result of the processing is the new state of the user-agent. The new state may either be steady or transient, based on the representation received in the response and it's metadata (media type). If the state is transient, the hypermedia-level logic automatically chooses requests for fetching other resources in order to bring the user-agent into a steady state so that application-level logic can take over.
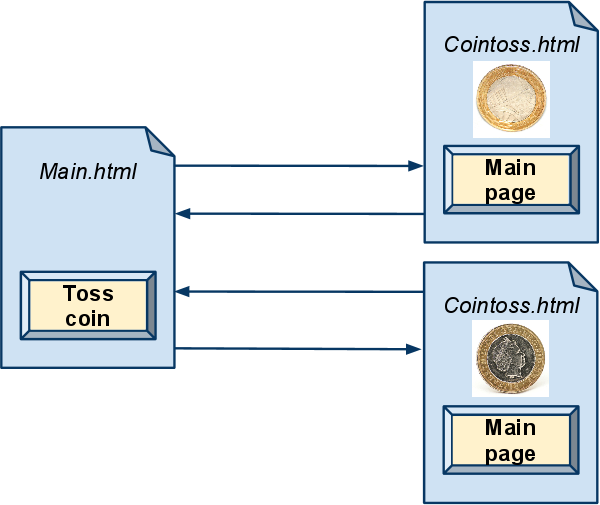
Now an example - applying this model to a specific RESTful system, which will of course be a simple web application shown above. The purpose of the web application is to simulate coin tossing. It has two web pages, Main.html and Cointoss.html. The Main.html page contains only a single link to the Cointoss.html page and nothing else. The Cointoss.html page has a link back to the Main.html page and a single image. Since the web application simulates coin tossing, which is nondeterministic, the image which gets included into the Cointoss.html is chosen randomly by the server and is either the heads.png image or the tails.png image.
The input symbols of the resulting automaton are requests for fetching application resources - the html pages and the images. The states of the resulting automaton are both steady states representing a complete page load or transient states representing partial page loads. Therefore, the Main.html page is represented by only a steady state since it only contains a link to Cointoss.html, while the Cointoss.html page is represented by both a transient state and a steady state since it contains an image which must be fetched after the initial page. Let's assume that the initial state contains a single link to the Main.html page. The transition function of the resulting automaton defines which responses the processing infrastructure returns for each state and requests. Therefore, if the user-agent requests a page or image, the server returns the requested page or image. However, if the user-agent is requesting the Cointoss.html page - it isn't known in advance what the server will return (heads or tails), so we need a nondeterministic transition into two possible states. Lastly, steady states define the set of acceptable states.
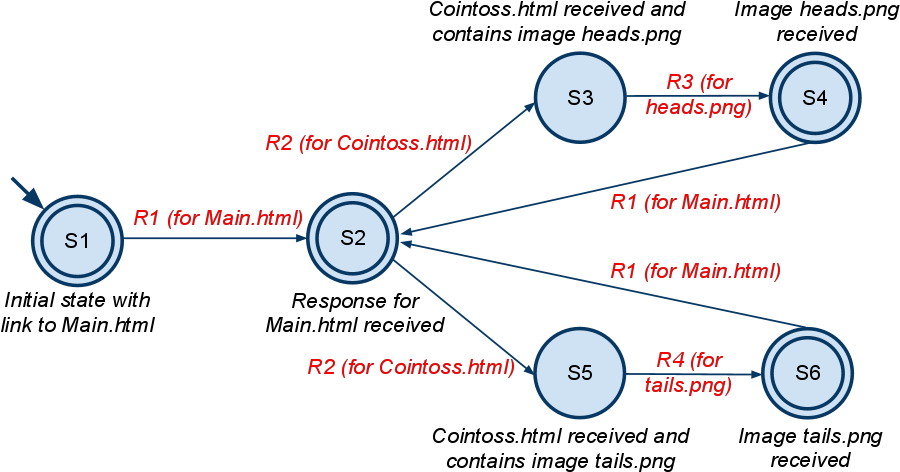
And here's the formal automaton definition for the explanation above:
- Σ = { R1, R2, R3, R4 }, where R1 is a request for fetching Main.html, R2 is a request for fetching Cointoss.html, and R3 and R4 are requests for fetching the heads.png and tails.png images. For simplicity, let's say these are the only input symbols the user-agent may generate, but in general - it may generate other syntactically valid requests.
- S = { S1, S2, S3, S4, S5, S6}, where S1 is the initial state containing a link to Main.html, S2 is the state after receiving the Main.html page, S3 is the state after receiving the Cointoss.html page which has a link to the heads.png image which hasn't been fetched yet, S4 is the state after receiving responses to both the Cointoss.html page and heads.png, S5 is the state after receiving the Cointoss.html page which has a link to the tails.png image which hasn't been fetched yet and S6 is the state after receiving responses to both the Cointoss.html page and tails.png.
- s0 = S1, since S1 is the initial state.
- The transition function is defined for each pair of automaton state and input symbol: δ(S1, R1) = S2, δ(S2, R2) = {S3, S5}, δ(S3, R3) = S4, δ(S4, R1) = S2, δ(S5, R4) = S6, δ(S6, R1) = S2. For other pairs of state and input symbol the function returns an empty set { } since there are no other links for those pages (states) to resources identified in those requests (input symbols).
- F = { S1, S2, S4, S6 }, since those states are steady.
And here’s the equivalent state diagram visualization of the automaton:
For such a model, we could generate a random sequence of input symbols and check if the automaton will end up in a steady state or not. You can do this for homework :).
Conclusion
(EDIT: inserted a few sentences to make this a real conclusion) That's about it. All-in-all, I think REST is an important concept for the WWW and that more work should be done to explain it fully and concisely. After that, we can simplify the models to reflect the most important properties, but simplifying before understanding leads to ignorance and misunderstanding in discussions.
If you have ideas or comments about systematizing knowledge, terminology and models for REST or developing formal models for REST - let me know. @izuzak
Comments